A Brief History of Data Systems

Context
Many a time it happens when our business or customer wants to implement Big Data approaches exploiting AI use cases. But they completely get lost in the number of buzzwords like Data Lake, Lambda Architecture etc.
In the past, I have prepared material for such business stakeholders and customers to build their foundation on data systems so that they can understand these buzzwords in a simplest non-technical manner.
Most of the time I ended up explaining how it all started and which approach or design pattern emerged or disappeared for what reason. So in this blog-post, I am trying to provide a brief history of how the data systems have evolved.
Almost all the definitions added here to further explain the terms used have been referenced from Wikipedia.
Single User
 Data systems’ journey started with a single user, a simple application running on a single machine.
Data systems’ journey started with a single user, a simple application running on a single machine.
Client-Server
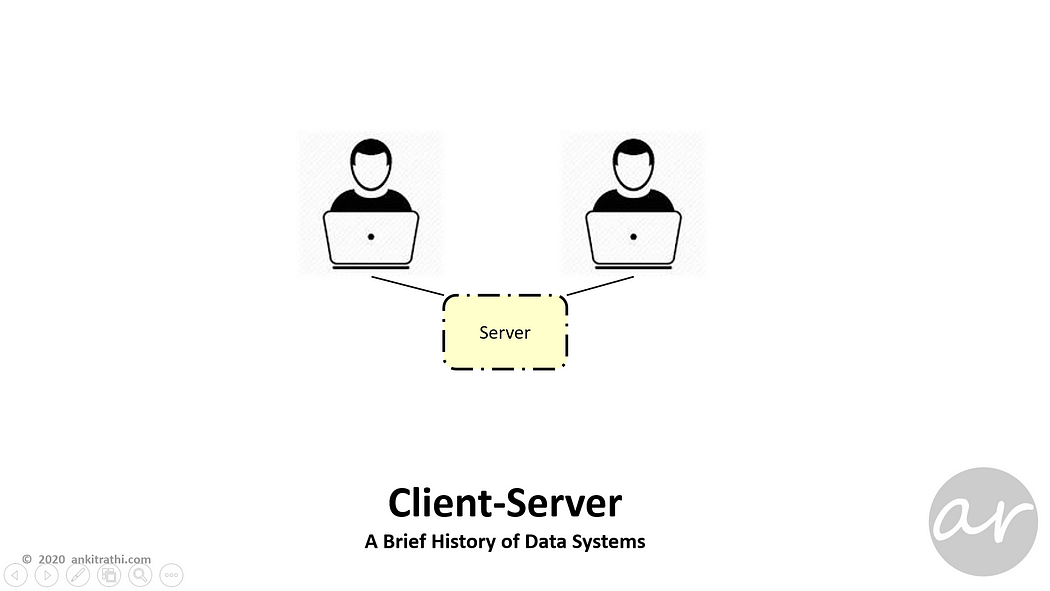 When multiple users needed to access data on the same server, Client-Server architecture followed, a thin client on the user’s machine connected to the server.
When multiple users needed to access data on the same server, Client-Server architecture followed, a thin client on the user’s machine connected to the server.
Client–server model is a distributed application structure that partitions tasks or workloads between the providers of a resource or service, called servers, and service requesters, called clients.
Front End & Back End
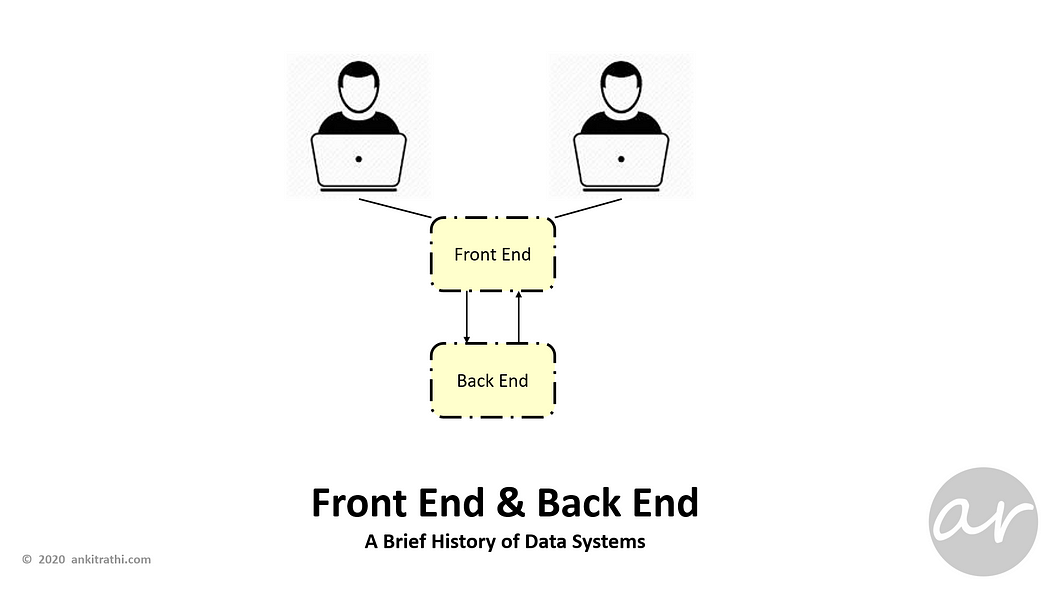 Over time, to better manage the users & data system, server further divided into front-end and backend, backend dealing with data and frontend tackling with users.
Over time, to better manage the users & data system, server further divided into front-end and backend, backend dealing with data and frontend tackling with users.
Database
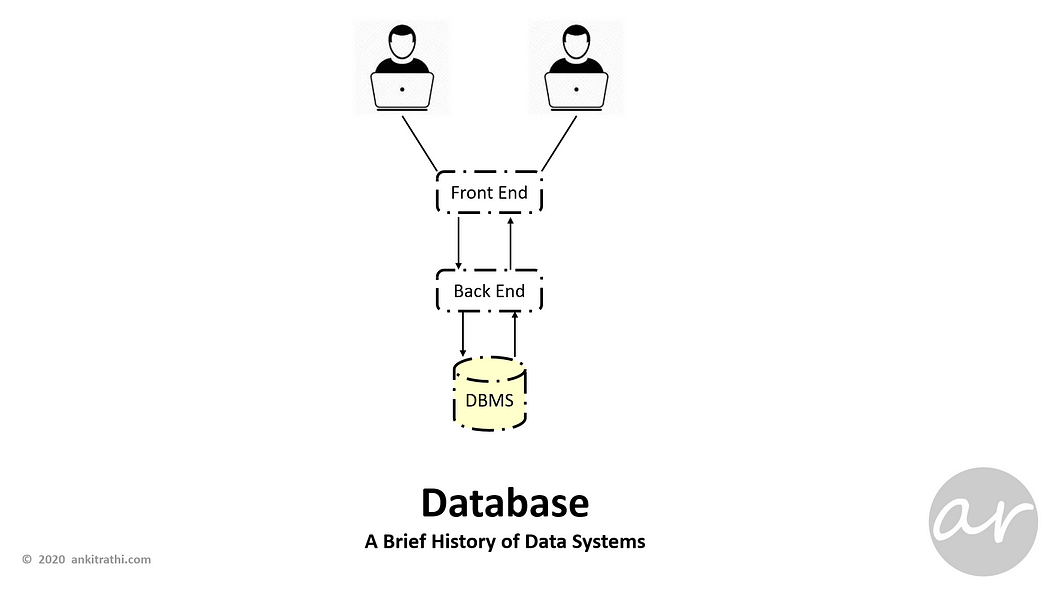 Database introduced to manage data efficiently and to allow users to perform multiple tasks with ease.
Database introduced to manage data efficiently and to allow users to perform multiple tasks with ease.
A database management system (DBMS) stores, organizes and manages a large amount of information within a single software application.
Business Intelligence
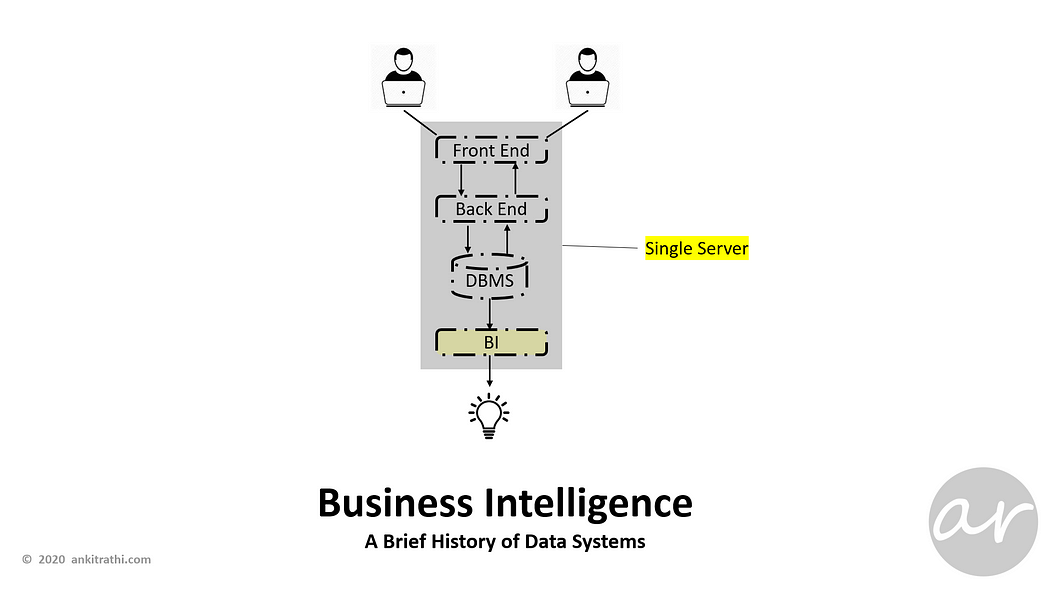 Business Intelligence (BI) function added at the other end of the database to get insights from operational data, till now this was all on a single machine.
Business Intelligence (BI) function added at the other end of the database to get insights from operational data, till now this was all on a single machine.
Business Intelligence comprises the strategies and technologies used by enterprises for the data analysis of business information. BI technologies provide historical, current, and predictive views of business operations.
More Users
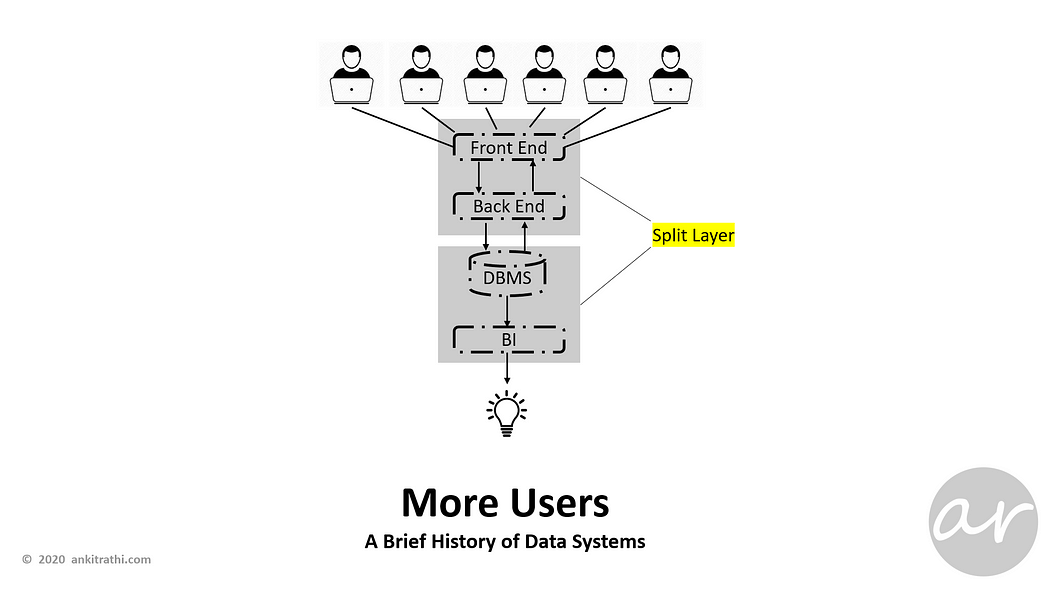 As users increased on the operational side, the single machine got split into two to manage different operational and analytical needs of the users.
As users increased on the operational side, the single machine got split into two to manage different operational and analytical needs of the users.
Even More Users
 As more users increased on the operational side, machines were added in parallel to manage the load.
As more users increased on the operational side, machines were added in parallel to manage the load.
Automated Systems
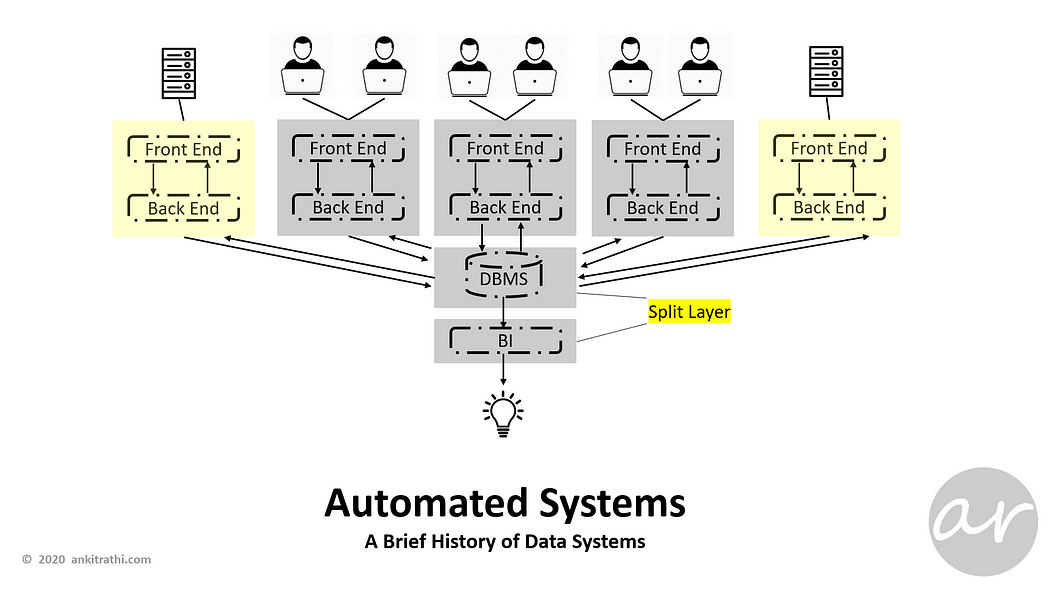 Addition of automated systems also put pressure on the database, BI layer got split to better manage BI concerns separately.
Addition of automated systems also put pressure on the database, BI layer got split to better manage BI concerns separately.
More Users (Analytics)
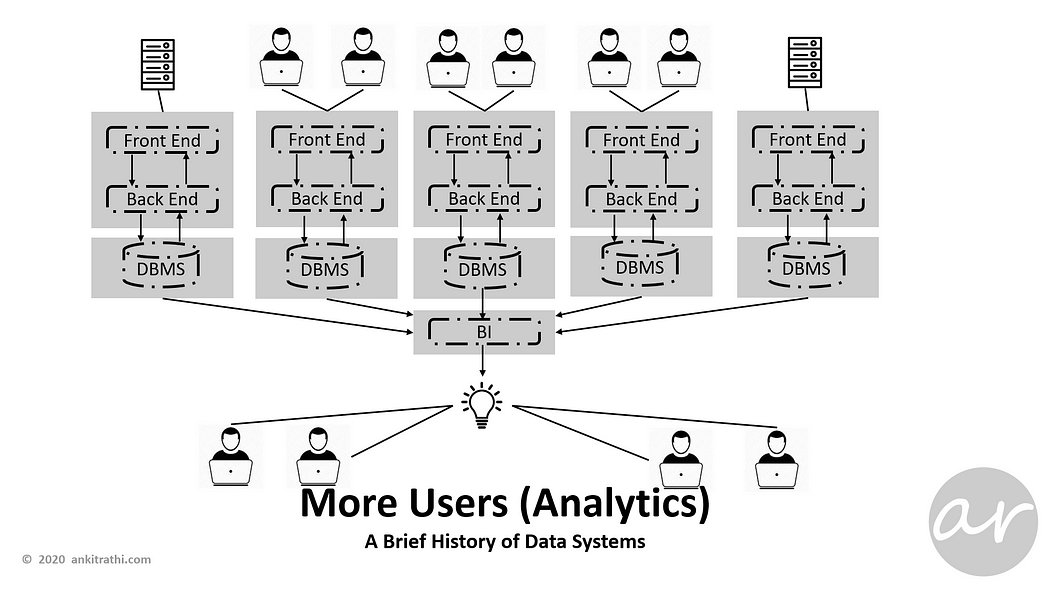 To manage the operational load, even databases were made available in parallel, which increased the load on BI, as well as introduced few problems in terms of inconsistency.
To manage the operational load, even databases were made available in parallel, which increased the load on BI, as well as introduced few problems in terms of inconsistency.
ETL & DWH
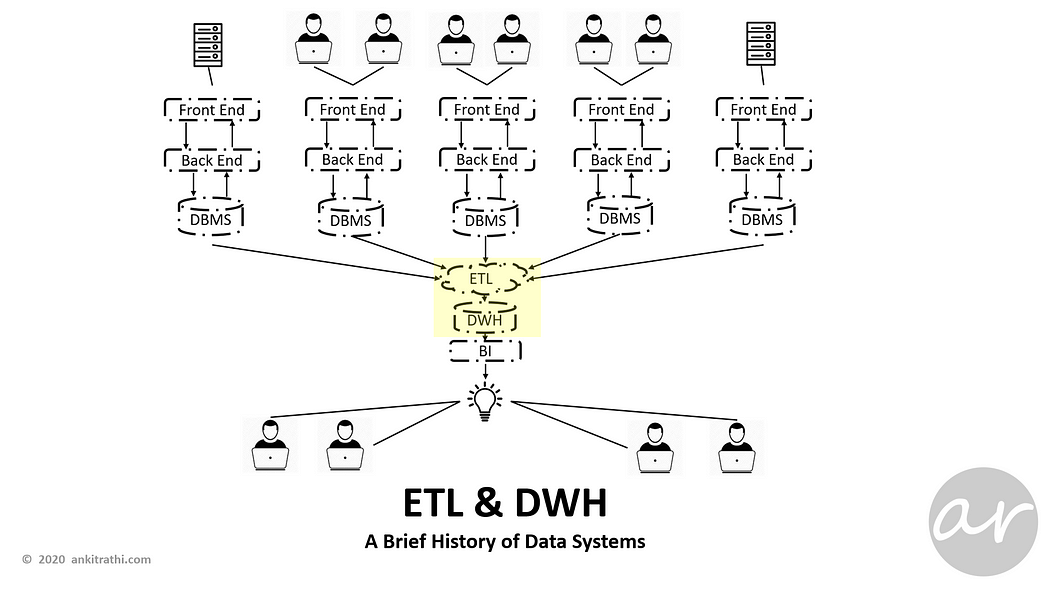 DWH and ETL layer allowed the consolidation of data, analysis and reporting for analytical users.
DWH and ETL layer allowed the consolidation of data, analysis and reporting for analytical users.
A data warehouse (DWH)is designed to support business decisions by allowing data consolidation, analysis and reporting at different aggregate levels.
The process of extracting data from source systems and bringing it into the data warehouse is commonly called ETL, which stands for extraction, transformation, and loading.
Data Mining & OLAP
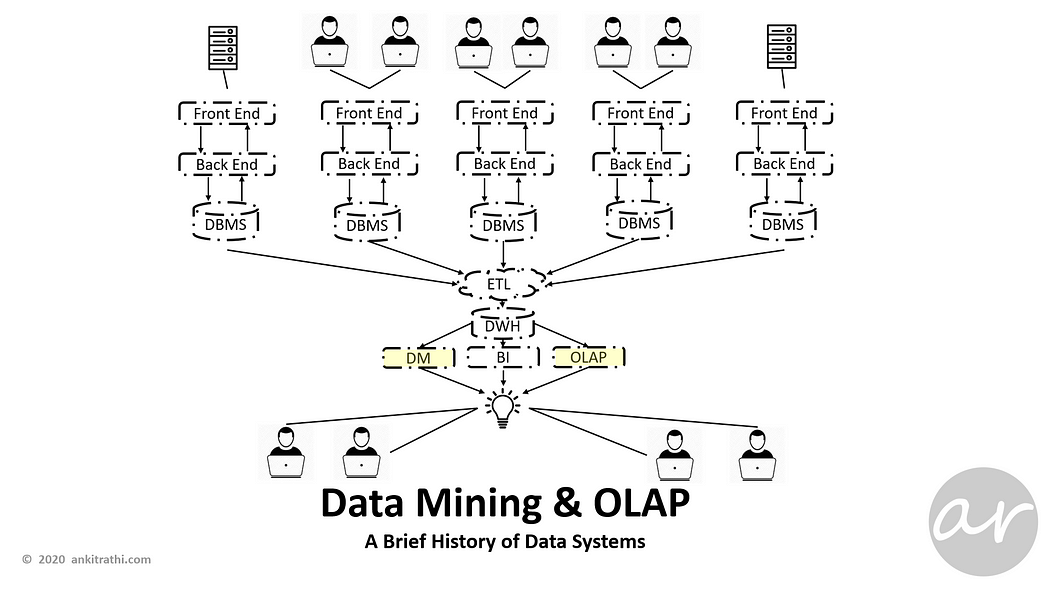 As time progressed, analytical needs increased, data mining (DM) and online analytical processing (OLAP) functions added.
As time progressed, analytical needs increased, data mining (DM) and online analytical processing (OLAP) functions added.
Data mining (DM) is the process of discovering patterns in large data sets involving methods at the intersection of machine learning, statistics, and database systems.
Extract, Load, Transform (ELT)
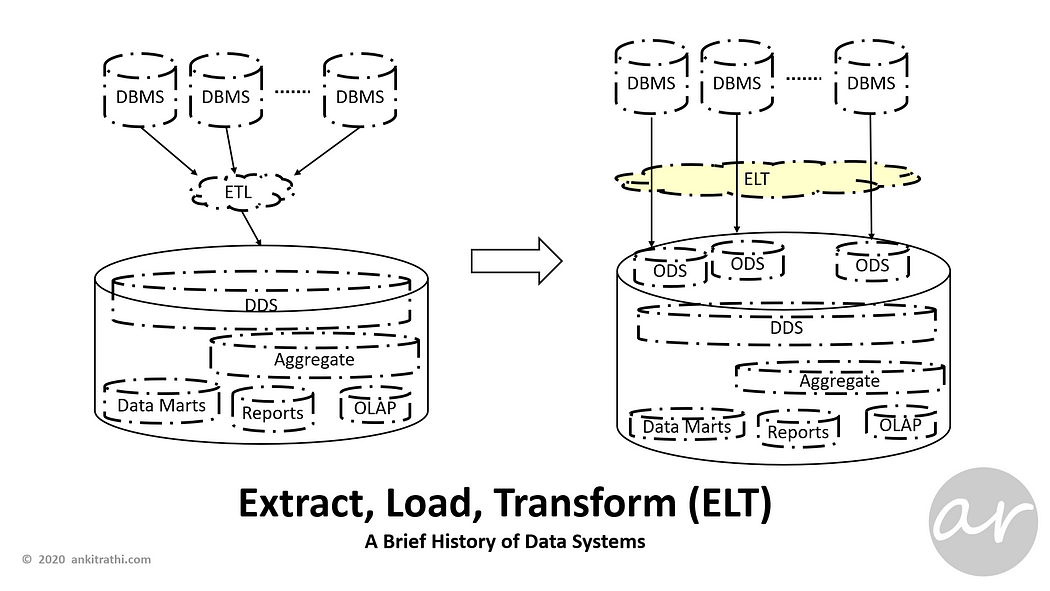 To reduce the dependencies on source data systems and minimize the latency, ELT pattern started being used.
To reduce the dependencies on source data systems and minimize the latency, ELT pattern started being used.
Extract, load, transform (ELT) is an alternative to extract, transform, load (ETL) used with data warehouse or data lake implementations.
Change Data Capture (CDC)
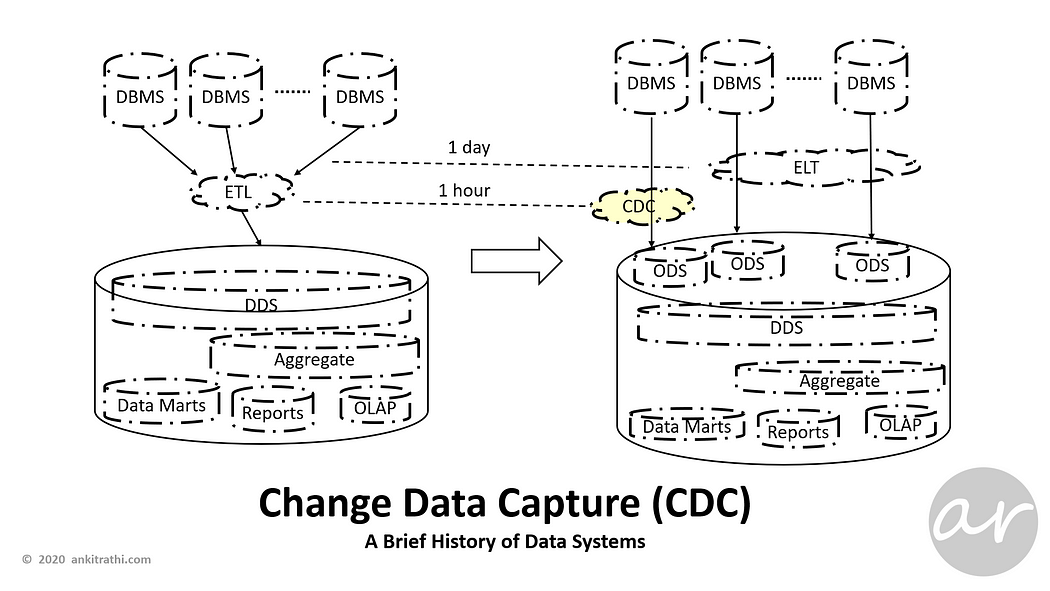 To further reduce the latency, change data capture (CDC) pattern introduced to transfer only the change-log rather actual data.
To further reduce the latency, change data capture (CDC) pattern introduced to transfer only the change-log rather actual data.
Change data capture (CDC) is a set of software design patterns used to determine and track the data that has changed so that action can be taken using the changed data.
Data Lake (Hadoop/Spark)
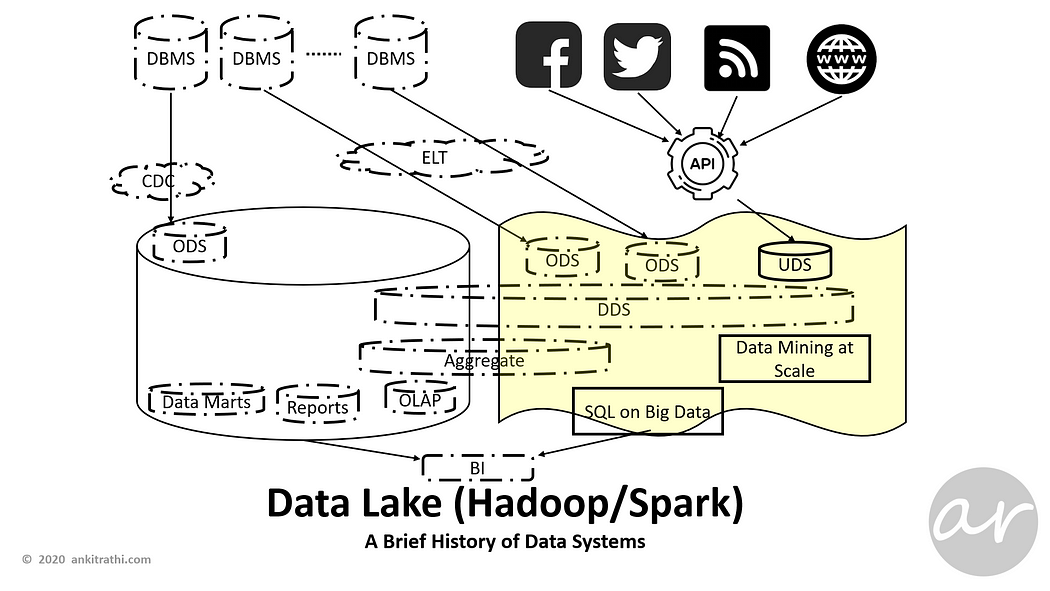 As analytics needs of organizations increased with less and less time-to-market as well as latency requirements, Data Lake was introduced to make the most of the rapidly evolving technologies like Hadoop and Spark.
As analytics needs of organizations increased with less and less time-to-market as well as latency requirements, Data Lake was introduced to make the most of the rapidly evolving technologies like Hadoop and Spark.
A data lake is usually a single store of all enterprise data including raw copies of source system data and transformed data used for tasks such as reporting, visualization, advanced analytics and machine learning.
Apache Hadoop is a collection of open-source software utilities that facilitate using a network of many computers to solve problems involving massive amounts of data and computation. It provides a software framework for distributed storage and processing of big data using the MapReduce programming model.
Apache Spark is an open-source distributed general-purpose cluster-computing framework. Spark provides an interface for programming entire clusters with implicit data parallelism and fault tolerance.
Data Science (ML/AI)
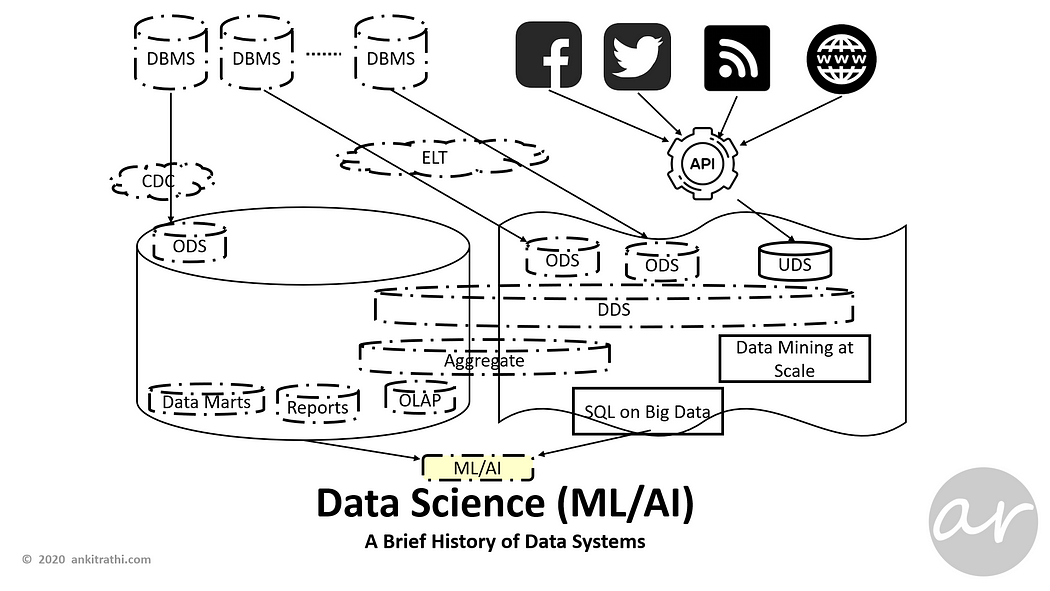 Due to recent advancement in the field of Artificial Intelligence, along with traditional analytics needs like BI, organizations started looking to leverage ML/DL use cases to gain competitive advantage.
Due to recent advancement in the field of Artificial Intelligence, along with traditional analytics needs like BI, organizations started looking to leverage ML/DL use cases to gain competitive advantage.
Data Science is an inter-disciplinary field that uses scientific methods, processes, algorithms and systems to extract knowledge and insights from many structural and unstructured data.
Machine Learning is the study of computer algorithms that improve automatically through experience. It is seen as a subset of artificial intelligence.
Artificial Intelligence, sometimes called machine intelligence, is intelligence demonstrated by machines, in contrast to the natural intelligence displayed by humans and animals.
Lambda Architecture
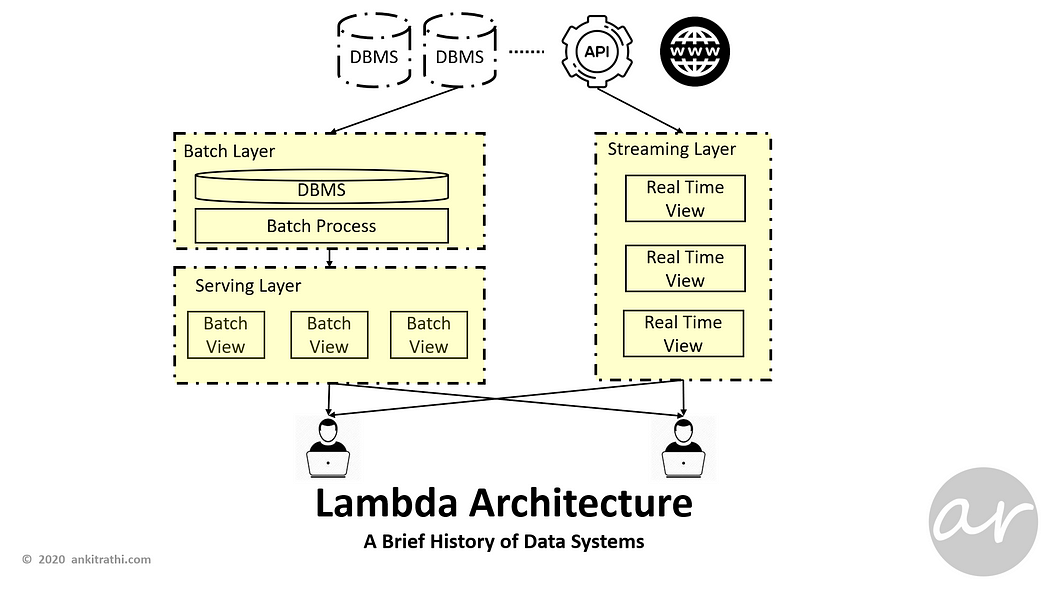 Along with batch processing and analytics, real-time processing and analytics also started gaining grounds. To eliminate the inconsistencies and overheads, Lambda Architecture was introduced.
Along with batch processing and analytics, real-time processing and analytics also started gaining grounds. To eliminate the inconsistencies and overheads, Lambda Architecture was introduced.
Lambda architecture is a data-processing architecture designed to handle massive quantities of data by taking advantage of both batch and stream-processing methods.
Kappa Architecture
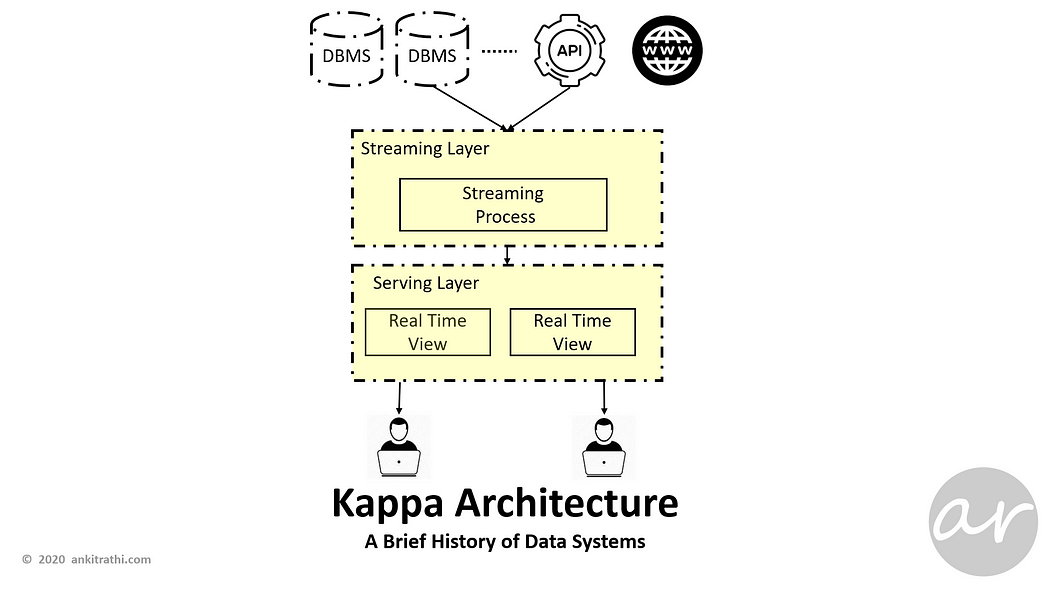 Lambda Architecture brings some complexities with it, Kappa Architecture is a simplification of Lambda Architecture.
Lambda Architecture brings some complexities with it, Kappa Architecture is a simplification of Lambda Architecture.
A Kappa Architecture system is like a Lambda Architecture system with the batch processing system removed. To replace batch processing, data is simply fed through the streaming system quickly.
Delta Lake
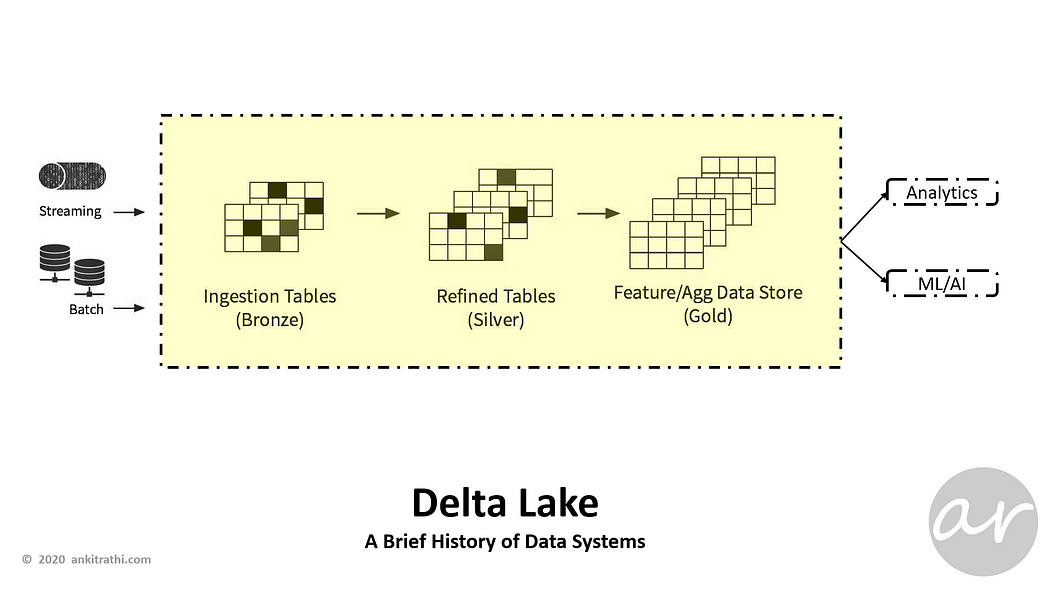 While Data Lakes are prominent in modern data architecture, it has its own problems. One of the major problems is lack of ACID capabilities, this problem has been solved by Delta Lake.
While Data Lakes are prominent in modern data architecture, it has its own problems. One of the major problems is lack of ACID capabilities, this problem has been solved by Delta Lake.
Delta Lake is an open source storage layer that brings reliability to data lakes. Delta Lake provides ACID transactions, scalable metadata handling, and unifies streaming and batch data processing. Delta Lake runs on top of your existing data lake and is fully compatible with Apache Spark APIs.
Distributed Data Mesh
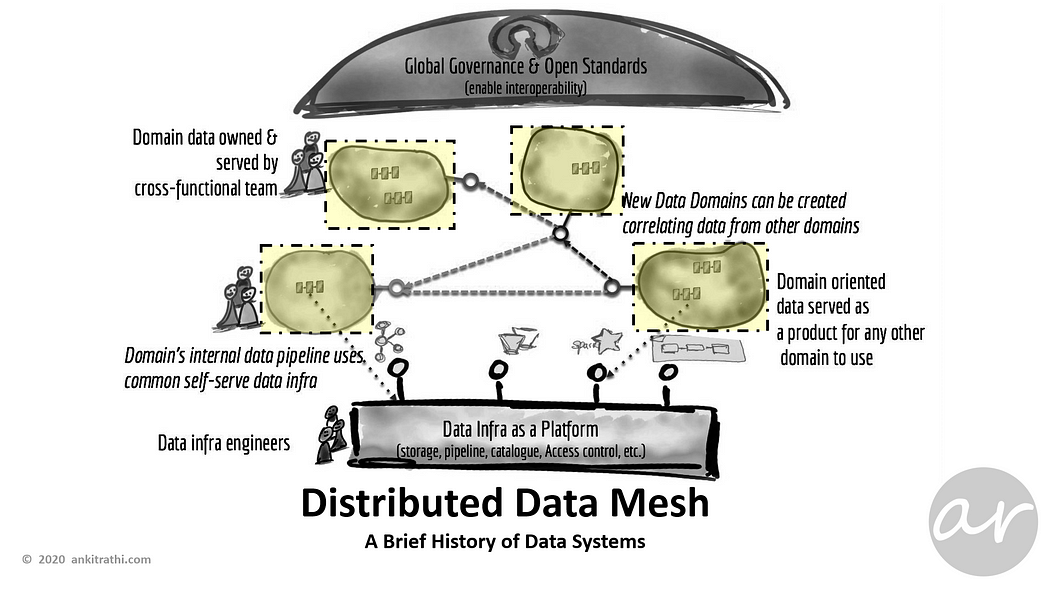 Data Lake and even Delta Lake still have some common failure mode, one of the most talked-about failures is centralized and siloed nature which substantially hampers the capability to make data and its business value made available across the organization.
Data Lake and even Delta Lake still have some common failure mode, one of the most talked-about failures is centralized and siloed nature which substantially hampers the capability to make data and its business value made available across the organization.
Distributed Data Mesh is an architectural paradigm that unlocks analytical data at scale; rapidly unlocking access to an ever-growing number of distributed domain data sets, for a proliferation of consumption scenarios such as machine learning, analytics or data-intensive applications across the organization.
Concluding Thoughts
This is it for now, as you may notice that Data Systems are evolving rapidly of late. In my view, there are two takeaways of this post:
Not one size fits all, which component or framework to use, it all depends on your specific requirement.
Even the latest approaches have inherent drawbacks (i.e. Data Lake, Distributed Data Mesh), the field will keep evolving and will be coming up with advanced methodologies.
I believe you found this blog-post helpful, do provide your valuable feedback.
Ankit Rathi is an AI architect, published author & well-known speaker. His interest lies primarily in building end-to-end AI applications/products following best practices of Data Engineering and Architecture.
Why don’t you connect with Ankit on YouTube, Twitter, LinkedIn or Instagram?
If you have any questions or comments, click the "Go To Discussion" button below!