Building Data Analytics Ecosystem
In this post, I am going to cover how you can build a data analytics ecosystem in your organization.
A business doesn’t think in terms of data and technology, it mainly focuses on business outcomes and what it can do to maximize the business value.

A business strategy is a high-level plan to achieve certain business outcomes. Data and technology may or may not be a part of it but in today’s era, data and technology are becoming more and more important and are becoming an integral part of the business strategy.
Data strategy is high-level planning how data can help realize business outcomes in terms of data solutions. A data platform is an ecosystem that enables stakeholders to materialize their data strategy into data solutions.
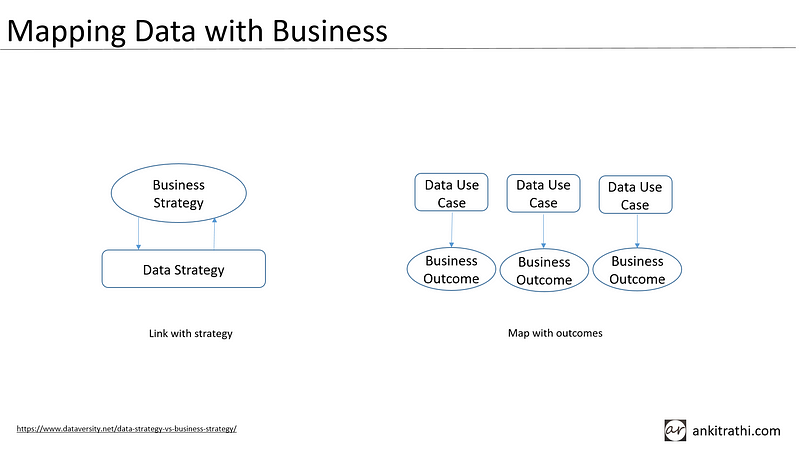
If we look closer, in order to maximize the business value of data, it becomes imperative to align business strategy with data strategy at the top and linking data use cases with business outcomes.
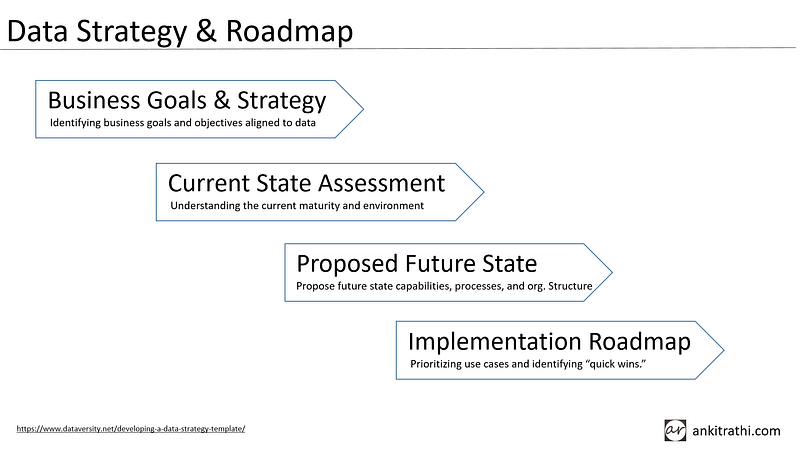
Now, how to build a data strategy, we can do it step by step. First, we need to identify business goals and objectives that we plan to achieve with the data we have or we can get. The next step is to evaluate the current state of the ecosystem. After that, we formalize the future state of the ecosystem i.e. what capabilities, processes, and structure we need to have in place. Once this is done, we identify the gaps between the current and future state and prepare an implementation roadmap.

As it turns out, we would be able to break the implementation roadmap into data use cases that we need to work on. Now let’s have a look at the template of a typical data use case. The very first thing that we need to do is to link the use case to the business goal. We need to define the problem/opportunity, define its business KPIs, mention the owner and consumer of the use case.
We need to see what data requirement this use case has and in case we have taken many use cases at a time, we need to assess the priority of the use cases.
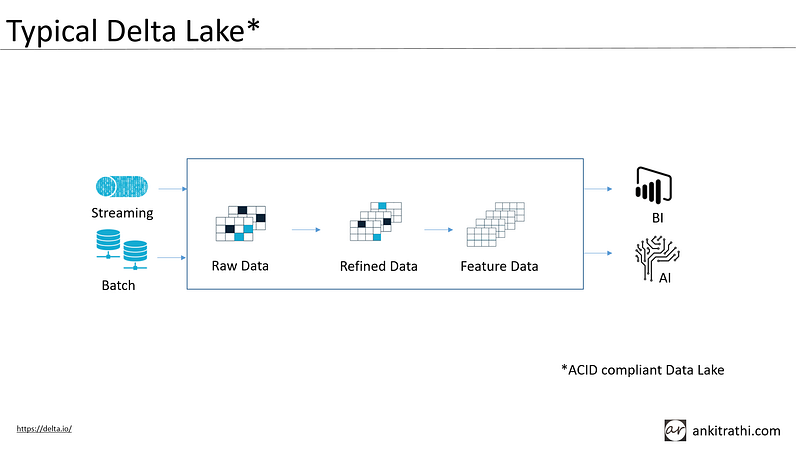
Delta Lake is an open-source storage layer that brings reliability to data lakes. Delta Lake provides ACID transactions, scalable metadata handling, and unifies streaming and batch data processing. Delta Lake runs on top of your existing data lake.
Delta Lake supports merging, updating, and deleting datasets. This allows you to easily comply with GDPR and CCPA and also simplifies use cases like change data capture.
Delta Lake has three stages of Data enrichment. Bronze tables contain the raw data ingested from various sources like JSON files, data from RDBMS systems, IoT data, etc. Silver tables provide a more refined view of the Bronze data. Gold tables provide business-level aggregates often used for reporting and dashboarding.
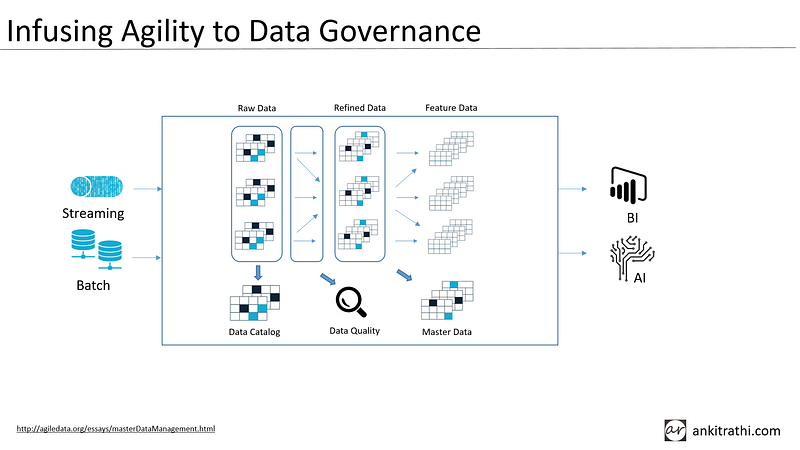
How you can infuse agility into your data governance? Data governance can be enforced from day one, but we can build it up gradually. We can have parallel pipelines in the platform to serve multiple use-cases and to make use of common raw and refined data.
Data catalog can be built on top of the raw data layer first, data quality checks can be put in place on data pipelines and master data can be built after refining the raw data.
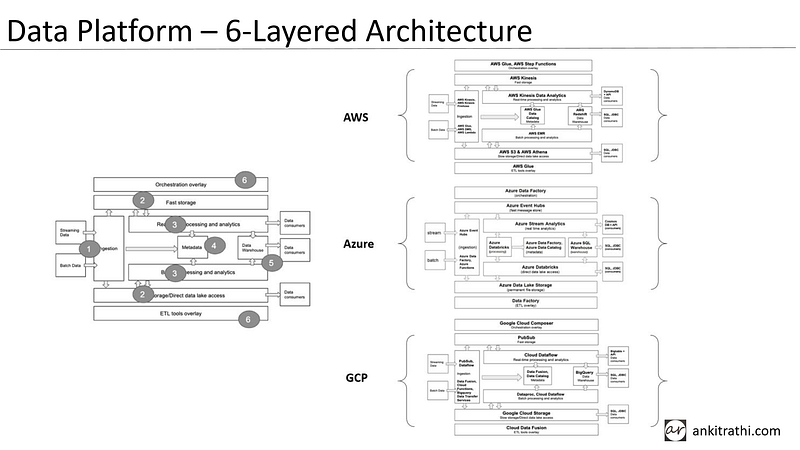
Now let’s have a look at the typical 6-layered data platform architecture which suffice most of the new age analytics requirements:
- In the ingestion layer, we show a distinction between batch and streaming ingest.
- In our storage layer, we introduce the concept of slow and fast storage options
- In our processing layer, we discuss how it works with batch and streaming data, fast and slow storage
- We add a new Metadata layer to enhance our processing layer
- We expand the Serving layer to go beyond a data warehouse to include other data consumers
- We add an Orchestration layer to automate data pipelines
AWS, Azure, and GCP have built respective components on their cloud platform to enable businesses to use data platform as PaaS, SaaS, or IaaS.
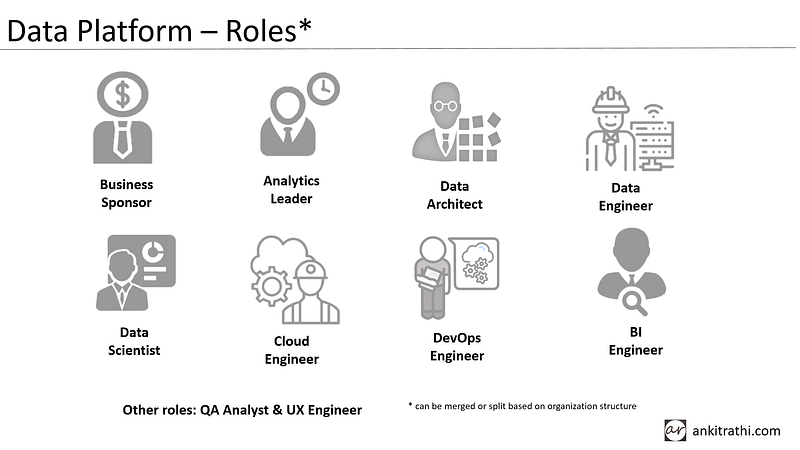
Now let’s have a quick look at the typical roles in a data platform.
Sponsors are business leaders who play a key role in promoting, advocating, and shaping data projects. Analytics leader oversees the execution of data analytics use cases and projects. The data architect looks after the overall data platform and ensures it meets the functional and non-functional requirements of the data analytics use cases. Data engineer builds data pipelines and data scientist takes care of analytics part of the use cases. Cloud engineer helps running data platform over the cloud. DevOps engineer automates the iterative steps in the data project lifecycle. BI engineer helps in presenting the insights to the consumers.

Let’s have a look at the high-level steps in order to build a data analytics ecosystem. First and foremost, build and align a data strategy aligning with business strategy. Then define the business outcomes we want to achieve and what data solutions we would require to achieve them. Based on this exercise, we assess AS-IS, propose TO-BE, identify the gaps and define the implementation roadmap.
Once the above steps are completed, we need to prioritize the data use cases based on ROI, picking low-hanging fruits first. Not every data use case is straightforward, we need to validate the feasibility with quick POC before taking up the use case as a full-fledged project.
We further develop, test, and deploy these data use cases as solutions. While working on the data platform, we need to data governance in an agile way and we need to automate, monitor, and maintain the data solution on the platform.
Ankit Rathi is a Principal Data Scientist, published author & well-known speaker. His interest lies primarily in building end-to-end AI applications/products following best practices of Data Engineering and Architecture.
If you have any questions or comments, click the "Go To Discussion" button below!