End-to-End Data Science Process

In this post, I am going to cover a typical end-to-end data science process.
Watch this episode on YouTube *here.*
From data science use-case identification to the deployment of the models in production, so much goes into data science projects.

So what is it like to work in a data science project? What are the high-level steps?
Let’s have a look in this post…
Before looking into the end to end data science process, I would like to quickly mention about data systems and the typical data lifecycle in an organization.
There are mainly two types of data systems: transactional and analytical.

Transactional systems support day to day business operations, while analytical systems enable better decision making.
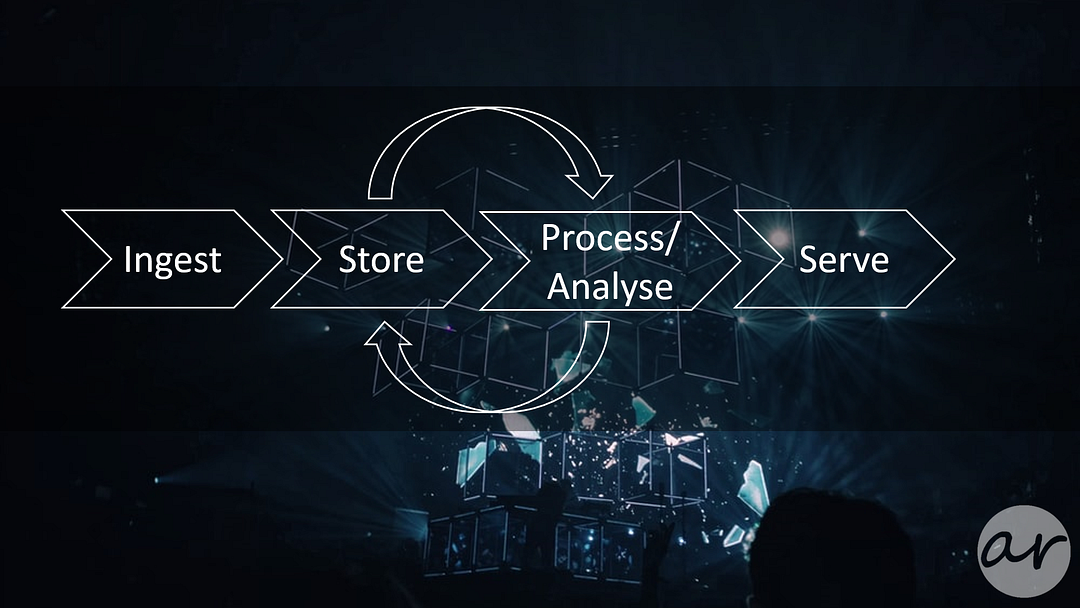
Basically, the raw data is collected, stored, processed, analysed and presented to business stakeholders as actionable insight.
As data gets old and less relevant, it can be archived and purged based on the requirement.
Now, let’s have a look at the high-level steps in a data science project.

The first step is Identify
Most of the time, you may start with defining the problem statement, but many a time, you may not have a problem at hand to solve.
In that case, you may need to first identify the use-cases for data science and may also need to qualify those use-cases.
If you have identified and qualified many use-cases, then you may also need to prioritize them based on their return-on-investment (ROI).

The next step is Define
After identifying the use case, you define the problem statement, you gather business or domain aspects and you start building your understanding around the data available.
You design a high-level approach for the solution, discuss and define the key-performance-indicators (KPIs) with the business sponsors.

The third step is Assess
Most of the time, it is worthwhile to start with a prototype or proof of concept (POC) rather than involving in a full-fledged project.
Building prototype is a way to assess the feasibility of the data science project before investing heavily, here you do all the steps required in a data science project but on a smaller scale.
Once you have built a prototype and stakeholders give a go-ahead, you start the project formally.

The next step is Build
You collect and explore the data, you validate and clean it, you apply transformations to make the data ready-to-be-consumed for core data science tasks.
Then you build the necessary features, split the train, validation and test data-set and also train, validate & tune the model.
Above steps are iterative, which means you would be continuously munging the data, building and modifying features; training, validating and tuning the models until you get the required results.

The fifth step is Deploy
Once your model provides required accuracy, you deploy it in an environment to get the feedback from business stakeholders.
After getting the positive feedback, you build required dashboards for business KPIs, and make your data science solution live.

The last step is Monitor
Once your model is in production, you need to monitor the data and model performance over the period of time for any performance degradation.
If a model performance goes down, you do a root-cause-analysis, replicate the issue in a different environment and repeat above mentioned steps to identify and resolve the issue.
So these are the six high-level steps in an end-to-end data science project.
I hope you like this post, let me know in the comments section.
Let’s end this post here;
Like, share & subscribe to my YouTube channel to get the latest updates.
Ankit Rathi is an AI architect, published author & well-known speaker. His interest lies primarily in building end-to-end AI applications/products following best practices of Data Engineering and Architecture.
If you have any questions or comments, click the "Go To Discussion" button below!